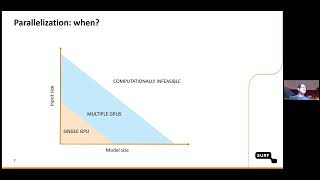
Quick Reader Guide: Discover how DDP harnesses multiple GPUs across machines to handle larger For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ...
Scaling Pytorch Distributed Data Parallel Model Parallelism - TV Overview
This page organizes Scaling Pytorch Distributed Data Parallel Model Parallelism with quick summaries, related pages, and practical search paths before opening more specific references.
In addition, this page also connects Scaling Pytorch Distributed Data Parallel Model Parallelism with for broader topic coverage.
TV Overview
Discover how DDP harnesses multiple GPUs across machines to handle larger For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ...
Pop Culture Common Checks
For changing topics, check updated sources and avoid depending on one short snippet alone.
Anime What It Connects To
Context matters because Scaling Pytorch Distributed Data Parallel Model Parallelism can connect to nearby topics, related searches, and different reader intents.
Drama Common Factors
Important details can vary by source, so this page groups the most readable points into a scannable format.
Key points worth scanning
- For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ...
- Discover how DDP harnesses multiple GPUs across machines to handle larger
How readers can use this page
The main value is that it gives readers a fast starting point without relying on one short snippet.
Helpful Questions
Why are related topics included?
Related topics help readers compare nearby references, explore similar searches, and avoid relying on one narrow result.
What should readers compare for Scaling Pytorch Distributed Data Parallel Model Parallelism?
Readers should compare source freshness, practical relevance, related options, requirements, limitations, and any details that affect their next step.
How does Scaling Pytorch Distributed Data Parallel Model Parallelism connect to entertainment?
Scaling Pytorch Distributed Data Parallel Model Parallelism can connect to entertainment when readers need context, examples, comparisons, or practical next steps inside the same topic area.